
 Автор:
Автор: Предисловие.
Веб-бот — это программа, которая автоматизирует ваши действия в интернете.
В этой статье, я объясню общий принцип создания ботов на Python, применив полученные знания, вы сможете создать бота который:
- Получает актуальную информацию о стоимости товара.
- Автоматически участвует в раздачах.
- Пишет сообщения от вашего имени (ссылка на урок).
- Скачивает картинки с сайта (ссылка на урок).
Приступим.
Создаем первого бота на Selenium.
Selenium — это библиотека для автоматизации действий в браузере.
Данный способ подойдет для любого сайта, однако, за все нужно платить. Selenium запускает браузер, отъедая огромный запас оперативной памяти. Используйте его только тогда, когда нужно выполнить JS код на странице.
Первым делом нужно установить библиотеку, для этого введите в консоли:
pip install seleniumДалее, установите веб-драйвер под браузер Firefox отсюда. Также, необходимо установить браузер Mozilla Firefox, если еще не установлен.
Теперь напишем простейшего бота. Для этого, напишите следующий python скрипт.
from selenium import webdriver #Ипортируем библиотеку
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
binary = FirefoxBinary('C:/Program Files/Mozilla Firefox/firefox.exe') #Прописываем путь до firefox.exe
browser = webdriver.Firefox(firefox_binary=binary) #создаем объект Firefox браузера
browser.get('https://under-prog.ru') #посредством метода get, переходим по указаному URLКод скрипта описан в комментариях.
Далее, переместите файл скрипта, в одну папку с веб-драйвером geckodriver.exe

И запустите python скрипт. У вас должен открыться браузер.
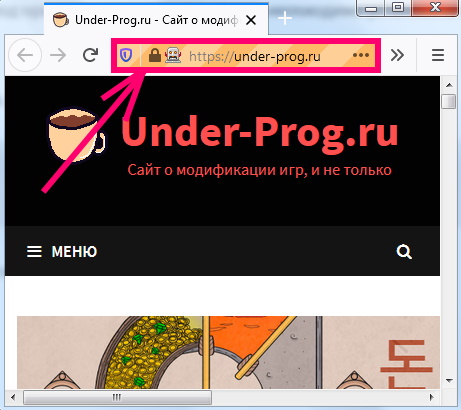
В адресной строке видна иконка робота, это значит, что браузером управляет программа.
Хорошо, бот создан, но он бесполезен. Единственное на что он способен, это заходить на сайт. Давайте добавим ему новых функций. Например, сделаем так, чтобы бот лайкал посты на сайте.
Бот лайкающий посты на сайте.
Последовательность действий у нас следующая.
- Зайти на сайт under-prog.ru (открыть браузер)
- Пройтись по каждому из постов.
- Нажать кнопку лайк, если она не нажата.
- Закрыть браузер.
Первый пункт мы уже сделали, перейдем ко второму.
Пройтись по каждому из постов.
На этом этапе, нужно понимать разметку HTML.
Зайдите на сайт, и нажмите кнопку F12.
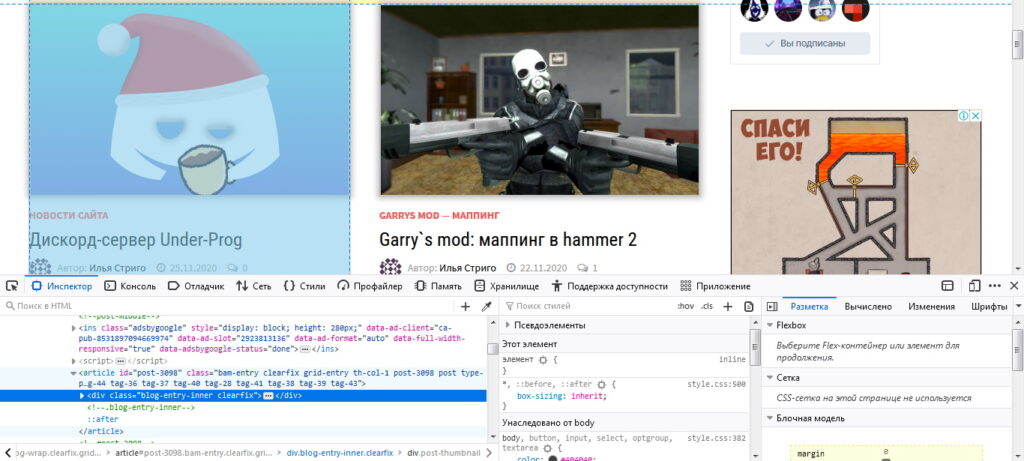
У вас откроются инструменты разработчика. Изучив разметку, мы понимаем, что все посты находятся в теге article.
Сейчас нам нужно получить ссылку, на каждый пост. Для этого будем использовать этот css селектор.
article div div.blog-entry-content header.entry-header h2.entry-title a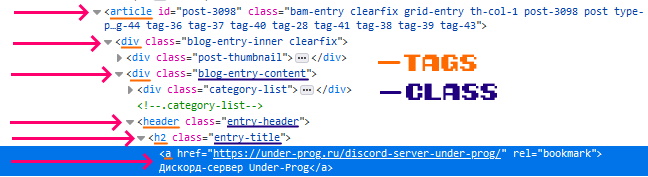
Данный селектор указывает:
- На элемент с тегом a
- который находится находится внутри тега h2 с классом entry-title
- тот, в свою очередь, находится внутри тега header с классом entry-header
- тег header находится внутри тега div с классом blog-entry-content
- тот, находится в теге div
- тег div находится внутри тега article
Теперь, дополним бота.
link = browser.find_elements(By.CSS_SELECTOR, 'article div div.blog-entry-content header.entry-header h2.entry-title a')[0].get_attribute('href')
print(link)Разберем новую функцию.
browser.find_elements(By.CSS_SELECTOR, css_селектор)Данная функция ищет элементы по css селектору. В результате своей работы, она возвращает массив элементов.
link = browser.find_elements(By.CSS_SELECTOR, 'article div div.blog-entry-content header.entry-header h2.entry-title a')[0].get_attribute('href')В-общем, мы из этого массива, достали первый элемент, и при помощи функции get_attribute(), получили значение атрибута href (ссылка на пост).
print(link)И вывели его на экран.
Запустите скрипт, в консоли должна появится ссылка на первый пост.
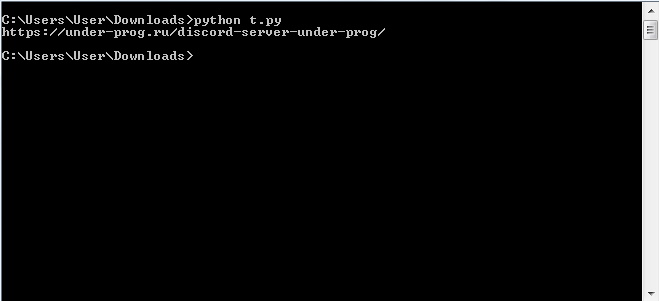
Если закинуть массив элементов в цикл, то получится извлечь ссылки на все посты.
from selenium import webdriver #Ипортируем библиотеку
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
binary = FirefoxBinary('C:/Program Files/Mozilla Firefox/firefox.exe') #Прописываем путь до firefox.exe
browser = webdriver.Firefox(firefox_binary=binary) #создаем объект Firefox браузера
browser.get('https://under-prog.ru') #посредством метода get, переходим по указаному URL
elements = browser.find_elements(By.CSS_SELECTOR, 'article div div.blog-entry-content header.entry-header h2.entry-title a')
for elem in elements:
print(elem.get_attribute('href'))
Отлично, ссылки на все посты получены, осталось всем этим постам, поставить лайк.
Нажать кнопку лайк, если она не нажата
Сначала перекопируем наши ссылки в отдельный массив. Замените это:
elements = browser.find_elements(By.CSS_SELECTOR, 'article div div.blog-entry-content header.entry-header h2.entry-title a')
for elem in elements:
print(elem.get_attribute('href'))На это:
elements = browser.find_elements(By.CSS_SELECTOR, 'article div div.blog-entry-content header.entry-header h2.entry-title a')
links_arr = []
for elem in elements:
links_arr.append(elem.get_attribute('href'))Далее напишем код, отвечающий за нажатие кнопки лайк.
for link in links_arr: #Проходим по каждому элементу массива ссылок
browser.get(link) #Переходим по ссылке
if browser.find_element(By.CSS_SELECTOR, 'button.wp_ulike_btn').get_attribute('class').find('wp_ulike_btn_is_active') == -1: #Если кнопка 'лайк' не нажата, тогда
browser.find_element(By.CSS_SELECTOR, 'button.wp_ulike_btn').click() #кликаем по кнопке 'лайк'Разберем данные строки.
if browser.find_elements(By.CSS_SELECTOR, 'button.wp_ulike_btn').get_attribute('class').find('wp_ulike_btn_is_active') == -1:Данная строка ищет кнопку с помощью css_селектора, и получает строку с названиями классов нашей кнопки.

Далее, при помощи функции find (стандартная функция python), мы получаем индекс подстроки ‘wp_ulike_btn_is_active‘, если не удалось найти подстроку, функция find возвращает -1, этим мы и воспользовались в нашем условии. Т.е. если атрибут ‘class‘ не содержит подстроку ‘wp_ulike_btn_is_active‘, то.
browser.find_elements(By.CSS_SELECTOR, 'button.wp_ulike_btn').click()Кликаем по кнопке лайк.
Осталось закрыть браузер, делается это с помощью функции quit().
browser.quit()Бот завершен, запустите скрипт, и наслаждайтесь автоматизацией.
Делаем браузер невидимым
Бот работает и все-бы ничего, но своим окном бразуера, он перекрывает все остальные окна. К счастью, у Firefox есть headless режим, позволяющий пользоваться функциями бразура, не открывая окно браузера.
Добавьте следующий код перед инициализацией браузера:
option = webdriver.FirefoxOptions()
option.headless = TrueЗдесь, мы переопредили настройки браузера, осталось передать их, нашему браузеру.
browser = webdriver.Firefox(options=option)Теперь, порядок.
Полный код бота:
from selenium import webdriver #Ипортируем библиотеку
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
binary = FirefoxBinary('C:/Program Files/Mozilla Firefox/firefox.exe') #Прописываем путь до firefox.exe
browser = webdriver.Firefox(firefox_binary=binary) #создаем объект Firefox браузера
browser.get('https://under-prog.ru') #посредством метода get, переходим по указаному URL
elements = browser.find_elements(By.CSS_SELECTOR, 'article div div.blog-entry-content header.entry-header h2.entry-title a')
links_arr = []
for elem in elements:
links_arr.append(elem.get_attribute('href'))
for link in links_arr:
browser.get(link)
if browser.find_element(By.CSS_SELECTOR, 'button.wp_ulike_btn').get_attribute('class').find('wp_ulike_btn_is_active') == -1:
browser.find_element(By.CSS_SELECTOR, 'button.wp_ulike_btn').click()
browser.quit()Итоговый результат.


