

 Автор:
Автор: Предисловие
На прошлом уроке вы познакомились с Selenium на практике, и сделали автоматизированного бота для накрутки лайков. В этом уроке вы научитесь обходить защиту cloudflare.
Цель.
Создать бота, который заходит на tf2.tm, и парсит цены на предметы.
Пишем бота
Для начала, попробуйте написать бота заходящего на этот сайт. Вы увидите следующую картину.
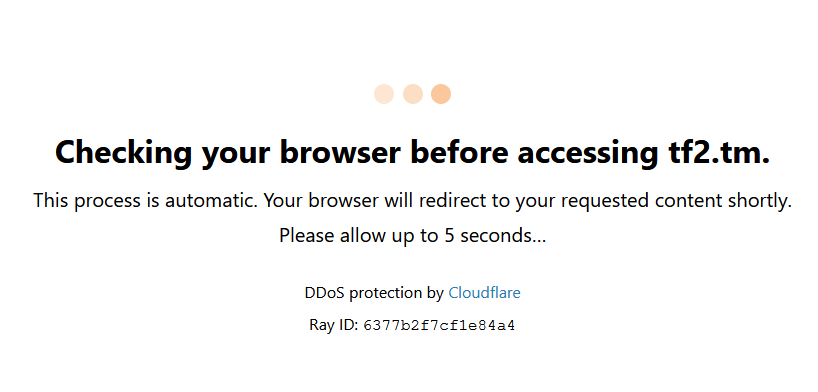
При загрузке страницы вылезает окно cloudflare, которое не даст пройти на сайт. Причина этому проста, браузер сам говорит сайту что он бот, исправим это, изменив один параметр.
option = webdriver.FirefoxOptions()
option.set_preference('dom.webdriver.enabled',False) #тот самый параметр
driver = webdriver.Firefox(options=option)Теперь попробуйте запустить бота.
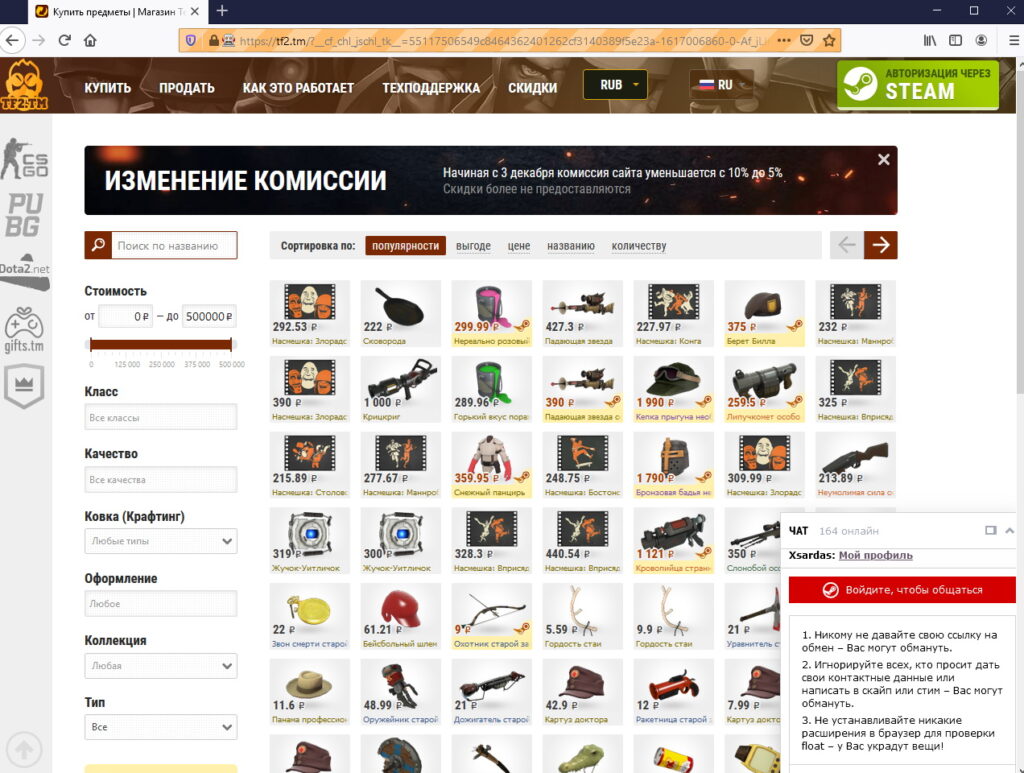
Прогресс. Двигаемся дальше.
Теперь нужно дождаться загрузки предмета на странице. Для этого нам понадобятся ожидания. Для работы с ожиданиями нам потребуются импортировать следующие библиотеки.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.firefox.firefox_binary import FirefoxBinaryДалее, перепишите данный код:
driver.get(f'https://tf2.tm/') #заходим на сайт
wait = WebDriverWait(driver, 60) # WebDriverWait указывает время ожидания в секундах
items_selector = '#applications a.item' # css-селектор элемента который мы ждем
wait.until(ec.visibility_of_element_located((By.CSS_SELECTOR,items_selector))) #Здесь мы ждем появления элемента item_selector, если в течении 60 секунд он не появится, произойдет исключениеУ WebDriverWait в функции until, указывается тип ожидания. В нашем случае это ec.visibility_of_element_located, ждем появления элемента. Ждать его мы будем 60 секунд (как и указали в WebDriverWait), если за это время элемент не появится, вызовется исключение. Элемент мы ищем с помощью css-селектора (By.CSS_SELECTOR).
Узнать об остальных типах ожидания можно в документации в графе Expected Conditions.
Теперь, соберем названия предметов и его цену, и выведем все это на экран.
items = driver.find_elements(By.CSS_SELECTOR, items_selector)
for item in items:
price = item.find_element(By.CSS_SELECTOR,'div.imageblock div.price').text
name = item.find_element(By.CSS_SELECTOR,'div.name').text
print(f'{name}: {price}')Похожий код я разбирал в предыдущем уроке. В итоге мы получили список цен предметов.
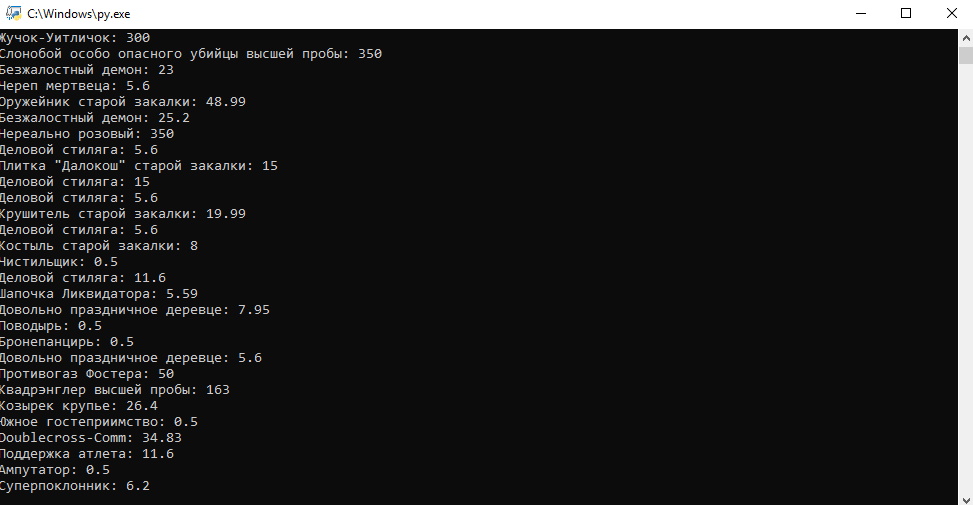
Заключение.
Теперь мы можем парсить любые сайты, где для доступа к информации не требуется авторизация. И это проблема, о сохранении куки браузера и последующей его загрузке, мы поговорим на следующем уроке.
Исходный код.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
def get_webdriver():
option = webdriver.FirefoxOptions()
# option.set_preference('dom.webdriver.enabled',False)
binary = FirefoxBinary('C:/Program Files/Mozilla Firefox/firefox.exe')
driver = webdriver.Firefox(options=option, firefox_binary=binary)
return driver
driver = get_webdriver()
driver.get(f'https://tf2.tm/')
wait = WebDriverWait(driver, 60)
items_selector = '#applications a.item'
wait.until(ec.visibility_of_element_located((By.CSS_SELECTOR,items_selector)))
items = driver.find_elements(By.CSS_SELECTOR, items_selector)
for item in items:
price = item.find_element(By.CSS_SELECTOR,'div.imageblock div.price').text
name = item.find_element(By.CSS_SELECTOR,'div.name').text
print(f'{name}: {price}')Итоговый результат.
