
 Автор:
Автор: Предисловие
В этом уроке мы создадим программу, которая выводит текущую цену ключа от ящика манн ко в рефах, с сайта stntrading.eu. Почему с stntrading.eu, а не с backpack.tf? Потому-что backpack.tf выдает неверную цену ключа. Да, да, не удивляйтесь. Помимо этого, он врет с ценой: спеллованных вещей, предметов призрачного типа, некоторых насмешек и скинов. А т.к. большинство людей сверяются с ценой backpack.tf, то можно… Ну вы сами поняли. Ладно, перейдем к делу.
Подготовка
Перед началом, установите нужные библиотеки, для этого, введите в командной строке:
pip install requests
pip install bs4requests — нужен для получения html страницы.
bs4 — нужен для парсинга этой самой страницы.
Теперь, нам необходимо узнать свой user-agent. Что-бы при заходе, сайт думал что вы зашли с браузера.
Получаем User-Agent.
- Для этого заходим в Mozilla Firefox, на любой сайт.
- Открываем меню разработчика (F12).
- Перезагружаем страницу.
- Заходим в графу сеть, и ищем первый GET запрос.
В графе заголовки запроса, найдите User-Agent.
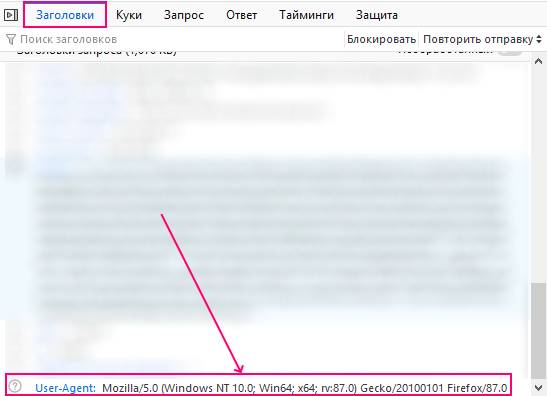
И сохраните это значение в текстовом файле.
Получаем содержимое страницы
Создайте Python скрипт и поместите туда следующий код:
# Импортируем библиотеки
import requests
from bs4 import BeautifulSoup
#Создаем словарь заголовков
header = {
#Сюда помещаем наш user-agent
'user_agent': 'свой_user_agent_пиши_здесь'
}
resp = requests.get('https://stntrading.eu/tf2/keys', headers=header).text
print(resp)В словаре header, замените user-agent , на собственный.
В данной строке:
resp = requests.get('https://stntrading.eu/tf2/keys', headers=header).textМы отправили GET запрос на сайт https://stntrading.eu/tf2/keys, в котором в качестве заголовков, передали собственный словарь заголовков (header).
И получили ответ от сервера, в виде текста (.text)
В итоге, мы получили содержимое html страницы находящийся по адресу https://stntrading.eu/tf2/keys.
Осталось распарсить данный текст.
Парсим html код с помощью BeautifulSoup.
Замените последние 2 строки, на это:
resp = requests.get('https://stntrading.eu/tf2/keys', headers=header).text
soup = BeautifulSoup(resp, 'lxml')
desc = soup.find('div',class_='d-none d-sm-block').findAll('h4',class_='description')
for d in desc:
if d.text.find('buying') > 0:
price = float(d.find('b').text.split(' ')[0])
print(price)В этой строке:
soup = BeautifulSoup(resp, 'lxml')Объект BeautifulSoup принимает 2 аргумента:
- Текст, который будем парсить.
- Сам парсер.
В качестве парсера был выбран lxml, т.к. это самый быстрый парсер html из доступных. Подробнее в документации.
desc = soup.find('div',class_='d-none d-sm-block').findAll('h4',class_='description')Для получения доступа к элементу, используется метод find, который имеет следующий синтаксис
Значения в квадратных скобках [] — не обязательны.
soup.find('тег', [class_='класс', id='id_тега'])- тег — тег нужного нам элемента (div, span, a, input)
- класс — класс нужного элемента
- id — id элемента.
Т.е. здесь:
desc = soup.find('div',class_='d-none d-sm-block').findAll('h4',class_='description')Мы ищем элемент с тегом div, и классом ‘d-none d-sm-block’
Внутри этого элемента, ищем все элементы (.findAll) с тегом h4 и классом description. В итоге получили массив элементов.
for d in desc:Проходимся по каждому элементу.
if d.text.find('buying') > 0:Если текст внутри тега h4 (d.text), содержит строку ‘buying‘, то:
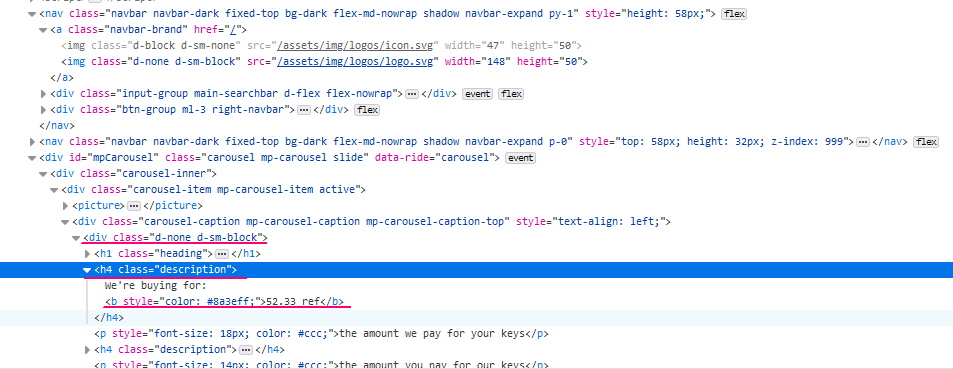
price = float(d.find('b').text.split(' ')[0])
print(price)Получаем текст внутри тега ‘b‘ (цену ключа), у него оставляем часть до пробела (.split(‘ ‘)[0]).
В заключение, выводим цену на экран.
Итоговый результат.

