

 by
by Preface
In the last lesson, you got acquainted with Selenium in practice, and made an automated bot to boost likes. In this lesson, you will learn how to bypass cloudflare protection.
Purpose.
Create a bot that goes to the tf2.tm, and parses the prices of items.
Writing a bot
For starters, try writing a bot coming to this site. You’ll see the following picture.
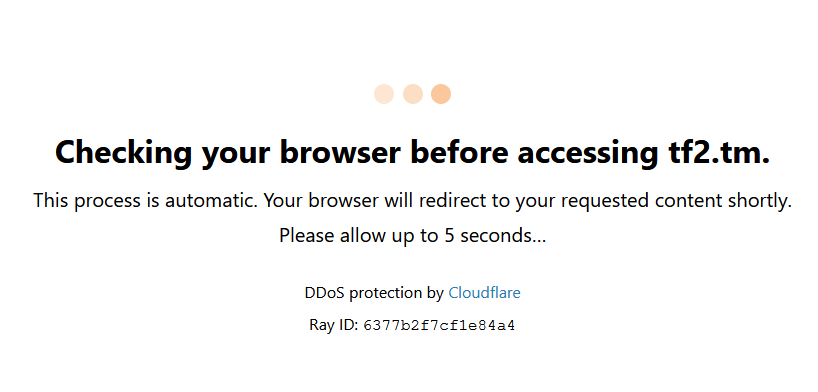
When the page loads, the cloudflare window comes out, which will not allow you to go to the site. The reason for this is simple, the browser itself tells the site that it is a bot, fix it by changing one parameter.
option = webdriver. FirefoxOptions()
option.set_preference('dom.webdriver.enabled',False) #тот parameter itself
driver = webdriver. Firefox(options=option)Now try running the bot.
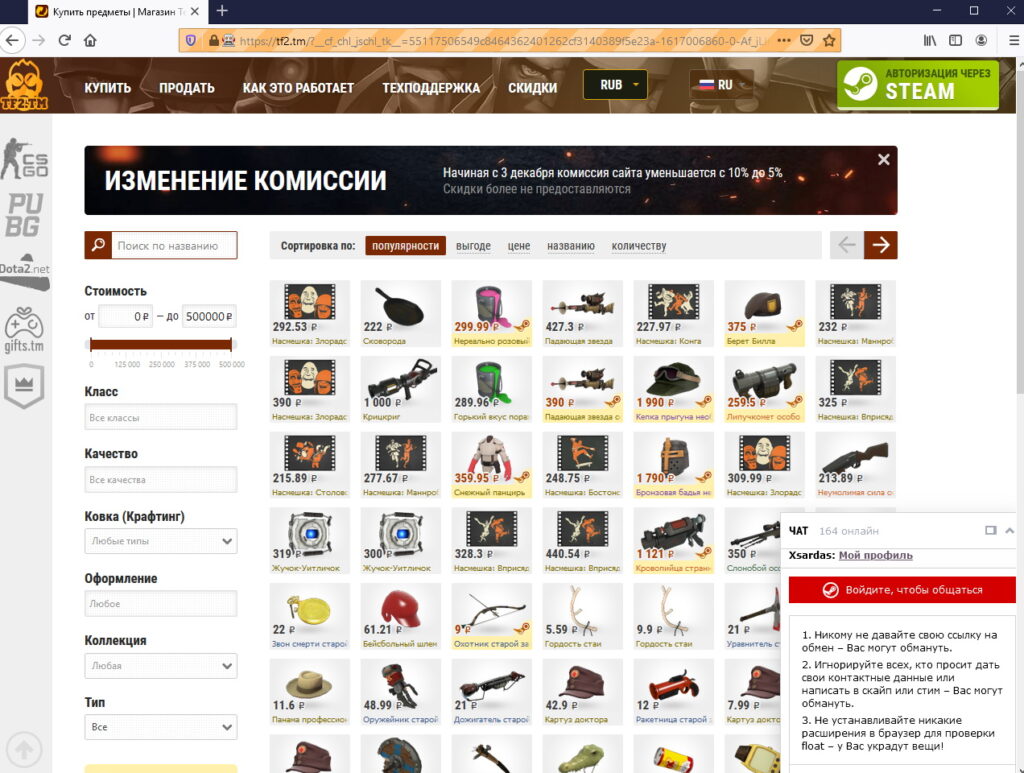
Progress. Moving on.
Now you need to wait for the item to load on the page. To do this, we will need expectations. To work with expectations, we will need to import the following libraries.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ecNext, rewrite this code:
driver.get(f'https://tf2.tm/') #заходим to the site
wait = WebDriverWait(driver, 60) # WebDriverWait specifies timeout in seconds
items_selector = '#applications a.item' # css-selector of the element we are waiting for
wait.until(ec.visibility_of_element_located((By.CSS_SELECTOR,items_selector))) #Здесь we are waiting for the appearance of the item_selector element, if it does not appear within 60 seconds, an exception will occurWebDriverWait has a pending type in the until , function. In our case, it is ec.visibility_of_element_located, waiting for the appearance of the element. We will wait for it for 60 seconds (as specified in WebDriverWait), if during this time the item does not appear, an exception will be thrown. We search for the element using the css selector (By.CSS_SELECTOR).
You can find out about other types of waiting in the documentation in the Expected Conditions column.
Now, let’s collect the names of the items and its price, and bring it all to the screen.
items = driver.find_elements_by_css_selector(items_selector)
for item in items:
price = item.find_element_by_css_selector('div.imageblock div.price').text
name = item.find_element_by_css_selector('div.name').text
print(f'{name}: {price}')I discussed a similar code in the previous lesson. As a result, we got a list of prices of items.
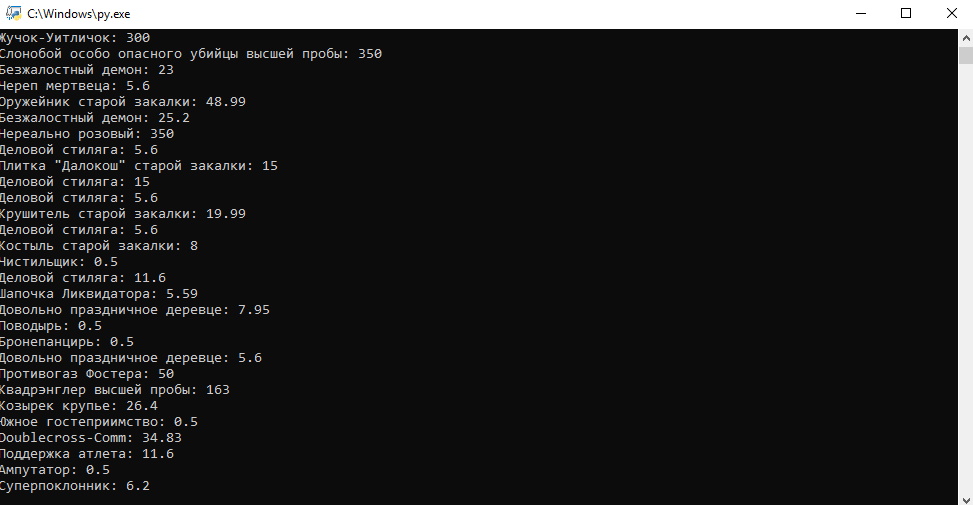
Conclusion.
Now we can parse any sites where no authorization is required to access the information. And this is a problem, about saving the browser cookie and then downloading it, we will talk in the next lesson.
Source code.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
def get_webdriver():
option = webdriver. FirefoxOptions()
option.set_preference('dom.webdriver.enabled',False)
driver = webdriver. Firefox(options=option)
return driver
driver = get_webdriver()
driver.get(f'https://tf2.tm/')
wait = WebDriverWait(driver, 60)
items_selector = '#applications a.item'
wait.until(ec.visibility_of_element_located((By.CSS_SELECTOR,items_selector)))
items = driver.find_elements_by_css_selector(items_selector)
for item in items:
price = item.find_element_by_css_selector('div.imageblock div.price').text
name = item.find_element_by_css_selector('div.name').text
print(f'{name}: {price}')
Final result.
