
 by
by Preface
In this tutorial, we will create a program that displays the current price of the key from the mann ko box in refs, from the site stntrading.eu. Why with stntrading.euand not with backpack.tf? Because backpack.tf gives out the wrong price of the key. Yeah, yeah, don't be surprised. In addition, he lies with the price: sintered things, ghostly items, some ridicule and skins. And since most people check with the price of backpack.tf,you can … Well, you get the understanding. Okay, let's get down to business.
Preparation
Before you begin, install the necessary libraries,for this, type at the command prompt:
pip install requests
pip install bs4requests – needed to get the html page.
bs4 – needed to parse this very page.
Now, we need to know our user-agent. That when entering, the site thought that you came from the browser.
We get a User-Agent.
- To do this, go to Mozilla Firefox,to any site.
- Open the developer menu (F12).
- Reload the page.
- Go to the networkgraph, and look for the first GET request.
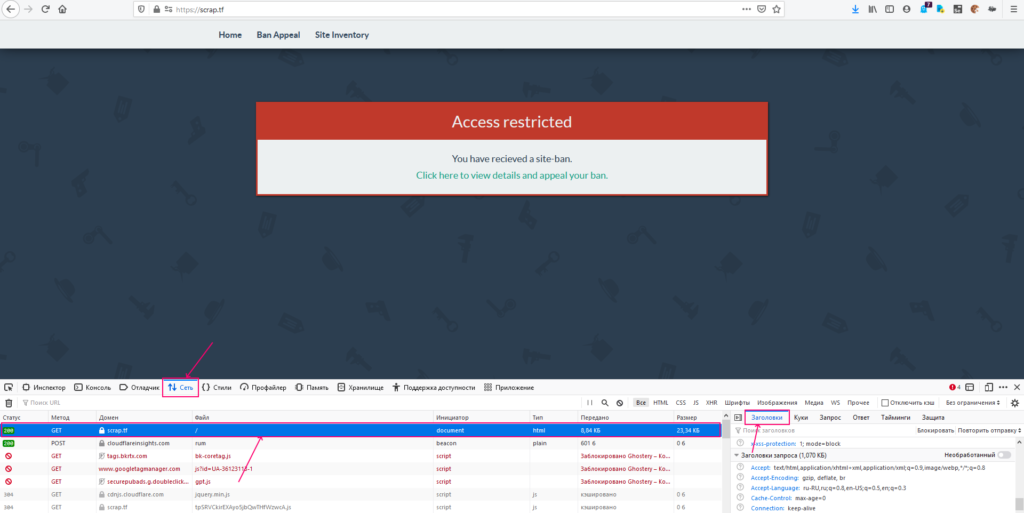
In the request headerscolumn, find the User-Agent.
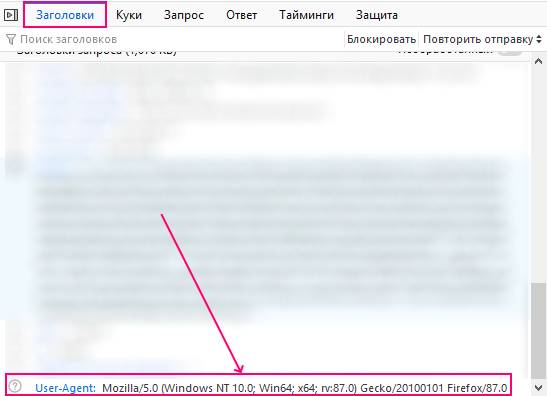
And save this value in a text file.
Get the content of the page
Create a Python script and put the following code there:
# Import libraries
import requests
from bs4 import BeautifulSoup
#Создаем dictionary of headings
header = {
#Сюда put our user-agent
'user_agent': 'your_user_agent_py_here'
}
resp = requests.get('https://stntrading.eu/tf2/keys', headers=header).text
print(resp)In the headerdictionary, replace user-agent with your own.
In this line:
resp = requests.get('https://stntrading.eu/tf2/keys', headers=header).textWe sent a GET request to the site https://stntrading.eu/tf2/keys,in which we passed our own header dictionary asheaders.
And received a response from the server, in the form of text (.text)
As a result, we received the content of the html page located at https://stntrading.eu/tf2/keys.
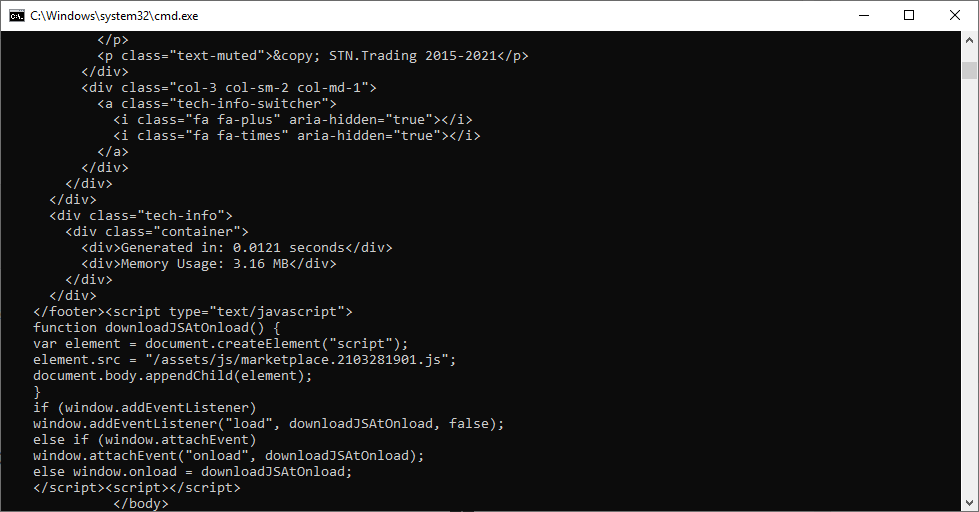
It remains to carp this text.
Parsim html code with BeautifulSoup.
Replace the last 2 lines with this:
resp = requests.get('https://stntrading.eu/tf2/keys', headers=header).text
soup = BeautifulSoup(resp, 'lxml')
desc = soup.find('div',class_='d-none d-sm-block').findAll('h4',class_='description')
for d in desc:
if d.text.find('buying') > 0:
price = float(d.find('b').text.split(' ')[0])
print(price)In this line:
soup = BeautifulSoup(resp, 'lxml')The BeautifulSoup object takes 2 arguments:
- Textthat we will parse.
- The parseritself.
Lxmlwas chosen as the parser because it is the fastest html parser available. Read more in the documentation.
desc = soup.find('div',class_='d-none d-sm-block').findAll('h4',class_='description')To access an item, use the findmethod, which has the following syntax
Values in square brackets [] are optional.
soup.find('tag', [class_='class', id='id_tag'])- tag – tag of the element we need (div, span, a, input)
- class – class of the desired element
- id – id of the element.
That is, here:
desc = soup.find('div',class_='d-none d-sm-block').findAll('h4',class_='description')We are looking for an element with a div tag, and a class 'd-none d-sm-block'
Inside this element, we look for all the elements (. findAll) with h4 tag and description class. As a result, we got an array of elements.
for d in desc:We go through each element.
if d.text.find('buying') > 0:If the text inside the h4 tag (d.text) contains the string 'buying', then:
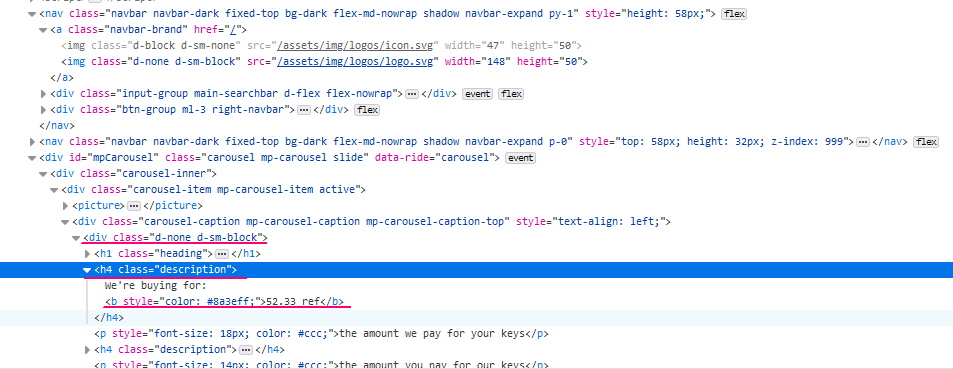
price = float(d.find('b').text.split(' ')[0])
print(price)We get the text inside the tag 'b' (key price), we leave a part to the space (.split(' ')[0]).
In conclusion, we display the price on the screen.
Final result.

